Nonlinear Model Cheating Sheet
Decision Tree
What is the model? decision tree?
标准答案
Types: Decision Tree is a supervised prediction model.
Describe: A decision Tree is a usually a k-nary tree. Each leaf denotes one classification or continuous value of the dependent variable.
Example:Two types of Decision Tree: Classification/Regression Tree
Decision Tree的特点
优点:他可以用来描述x和y之间更复杂的关系,建模能力更强(有人用来直接feature selection)
缺点:严重overfitting
How to determine this model?Build a Decision Tree?
Build Tree
Feature prioritization(一层在哪)
Feature splitting(每一层分几个)
相当于你每层都在对一个features进行切割(你想象成为scenario tree)
How to build(ID3 Algorithm)?
At each iteration step, we split the feature which can give us the largest entropy gain
definition of entropy熵/Entropy of the current system
Condition entropy: (现在在之前那个entropy下,看看变化)
Information gain = Entropy - Conditional Entropy
How to build(geometric)?
How is the performance of this model?
How to know decide which feature first?
tree regression: RSS ?
tree classification: 如何判定好坏,比较前后的misclass的比例;用三个不同的entropy&gini
Classification error rate E=1−maxk(p^mk)
Gini Index:G=∑k=1Kp^mk(1−p^mk)
cross-entropyD=−∑k=1Kp^mklogp^mk
Tree Pruning
解决overfitting(属于哪个部分),不能用Regularization(因为你没loss function呀)
How can we compare this model with others model?
Compare with GAM&linear regression
E[Y∣X1,⋯,Xp]=α+f1(X1)+⋯+fp(Xp)−Generalized additive model(GAM)
不是线性,是因为不是多项式
decision tree:f(X)=∑k=1Kcontribution(xk)==∑k=1KckI(X∈Rk)
这里的表示的是输入数据第个feature 对输出结果产生的作用,它可能是信息熵/gini impurity(见下一小节)的减少。
linear regression:f(X)=β0+∑j=1KXjβj
在LR里面中, 这项对的contribution是确定的,只与自己的取值和对应的系数有关
Decision tree中的的取值,不仅仅与有关,也与中其他feature所决定的整个decision path有关(可以看到前面例子real avatar,不止对前面和后面两个feature都有影响)(更具体地说,feature在path上的先后顺序不同,它的contribution就会不同)
很明显,这是一个非线性关系
Tree Model with ensemble method
Picture says everything!
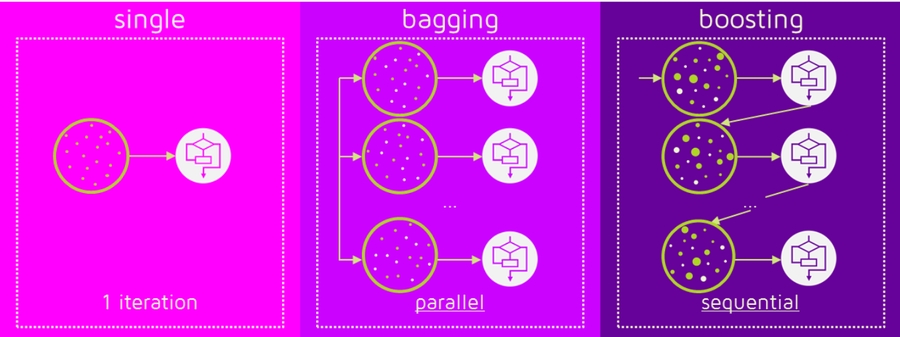
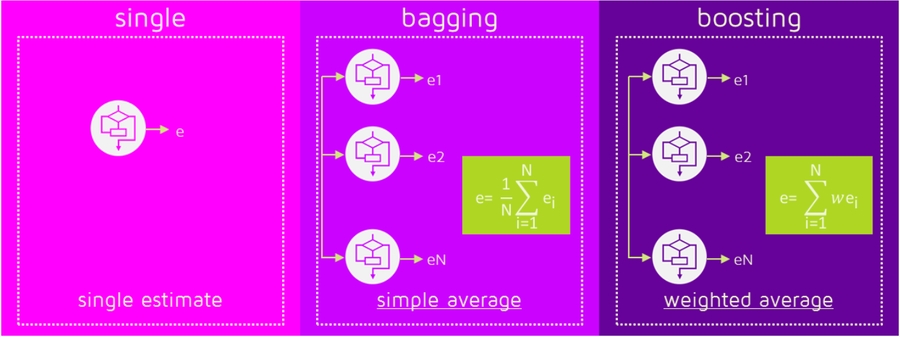
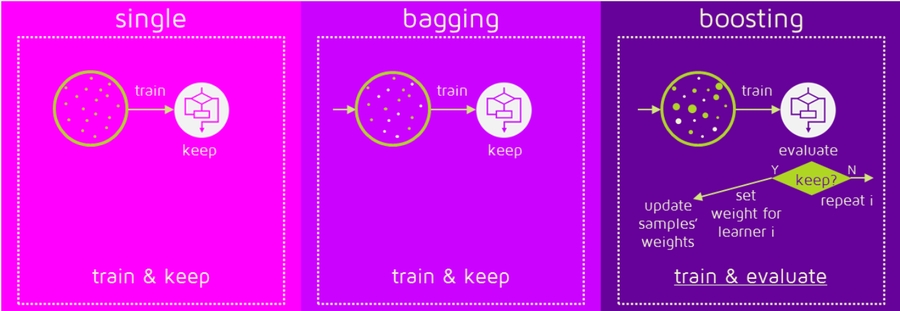
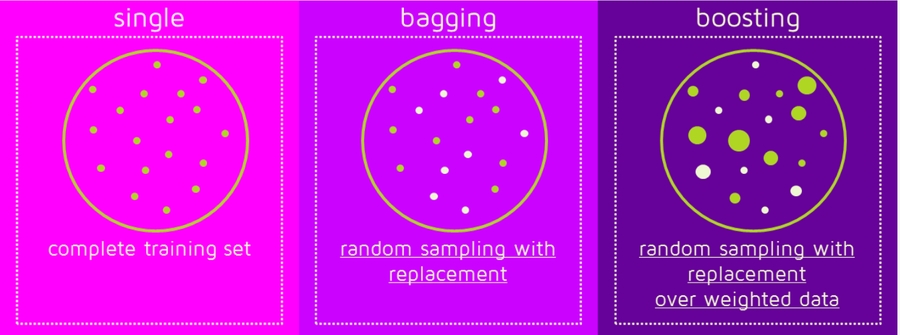
Why ensemble method
In ensemble learning, we train multiple learners to solve the same problem.
这些方法的出现,原本是为了来帮助decision tree,让一个本来variance很高,但bias比较低的进行一些转变.由于decision tree 的variance会比较大,bias小,所以可以用ensemble的方法
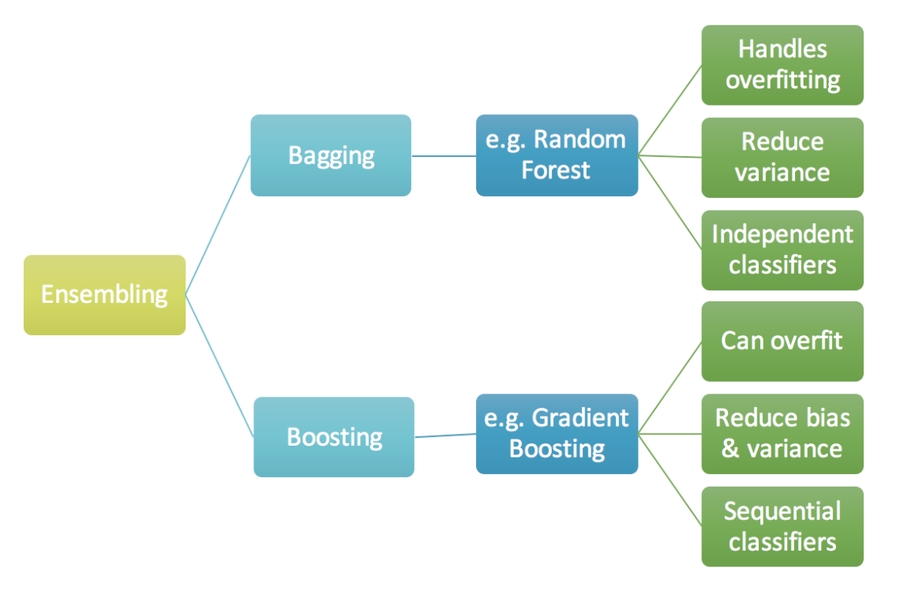
Ensemble learning including boosting method(Adaboosting) and bagging method(random forest).
Bagging
What is bagging?
types:
ensemble method
describe:
many independent predictors/models/learners & combine them using some model averaging techniques (e.g. weighted average, majority vote, or normal average)
same with replacement
advantage:
handle overfit/reduce variance/independent classifiers
example:
take random sub-sample/bootstrap of data for each model/ little different from each other
each observation/same probability in all models
Masterpiece: random forest
What is random forest?
types:
describe:
bagging for data
sampling for features
advantage:
In the random forest algorithm, we do NOT need to do pruning for each 'weak' decision tree.
less overfitting(你random后那些不重要的更不重要了,其实也是CLT)
parallel implementation
How to determine this model?
How is the performance of this model?
Feature Importance value in random forest
importance(i)=performance(RF)−performance(RF random i)
It does not signify a positive or negative impact on the class label. It only judges how much class discriminatory information each variable contains.
How can we compare this model with others model?
Boosting
What is boosting?
types:
ensemble method
describe:
the predictors are not independently but sequentially.
employs the logic which the subsequent learn from the mistakes of the previous predictors
the observations have an unequal probability of appearing in subsequent models and ones with the highest error appear most
The predictors can be chosen from a range of models like decision trees, regressors, classifiers
Because new predictors are learning from mistakes committed by previous predictors, it takes less time/iterations to reach close to actual predictions
but we have to choose the stopping criteria carefully or it could. lead to overfitting on training data.
advantage:
example:
Gradient Boosting
Masterpiece: Gradient boosting
What is gradient boosting?
How to determine this model?
相当于你一直调整你的拟合residual, 你每一次都是估计你的residual, 就是x 和loss function ,你用gradient处理
第二次, 你再找新的剩下的loss function, 用gradient帮助你
example?
Gradient Boosting: Gradient Descent On Function
Gradient boosting can be seen as gradient descent on function space.
In gradient descent we fixed the function and update the parameters(theta) by substracting the derivative of loss on thetaIn gradient boosting, we fixed the training algorithm and updated the model by adding the derivative of the loss on our model.
Gradient boosting is a framework where you can plug in any training algorithm and any loss function (as long as it is differentiable). Adaboost is one especial case of gradient boosting. It uses exponential loss
adaboost和xtboosting你需要懂,为了面试
How is the performance of this model?
How can we compare this model with others model?
Gradient Descent
example

learning rate/standardization
stochastic gradient descent
Bagging VS Boosting
bagging是有放回抽样,你的模型很简单,所以bias很低,因为你没有把模型复杂
boosting, sequential,所以的模型复杂,你的bias就会减小(废话你一直在找最优解),一定程度上减少virance
KNN
What is the model?
用你周围人的结果决定你
K denotes the k labels that are 'closest' to your target sample
the higher K is, the smoother(most robust) your model can be.
How to determine this model?
Find the top K closest distance from your returned unsorted distance array(heap sort会提到) /code!!!
给定测试样本,基于某种距离度量找出训练机中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测;
在分类任务中使用“投票法”,即选择这k个样本中出现最多的类别标记作为预测结果。
在回归中使用‘平均法’,即将这k个样本的实际值输出的标记的平均值作为预测结果
How is the performance of this model?
CityBlock Distance, Euclidean Distance, Gaussian Distance
How can we compare this model with others model?
Last updated